- 作者:一流科技
- 发表时间:2021-02-25 14:41
- 来源:未知
本文是OneFlow系统设计分享系列文章的中篇,主要介绍OneFlow的编译期Compiler如何将Job编译为Plan的。其中最精华的部分是OneFlow的Boxing模块,负责构建两个逻辑上的Op对应的两组物理上的Op在任意情形下的物理子图,完成了分布式训练中各个机器各个设备之间的数据拷贝、切分、传输、通信的子图搭建。值得一提的是,Boxing模块的代码实现是非常直观且易扩展的,使用了设计模式中的责任链模式(Chain of Responsibility),未来我们会结合OneFlow的代码实现分享一些C++编程技巧的文章,以及为什么OneFlow要使用这些编程技巧,解决了哪些问题,敬请期待~
https://github.com/Oneflow-Inc/oneflow
如果您对OneFlow这套致简致快的框架设计感兴趣,或者对深度学习框架、分布式系统感兴趣的话,本文就会让您完全掌握OneFlow的系统设计。相信读完这篇文章,您就会理解我们是如何看待分布式深度学习训练的,我们为什么要这样设计,这样设计的好处是什么,以及我们为什么相信OneFlow这套设计是分布式深度学习训练框架的最优设计。全文的主要内容如下:
全文分上、中、下三篇。本文是中篇。
这三篇系列文章会偏重于工程实现细节,所以会引用大量的OneFlow源码,适合对OneFlow底层代码实现感兴趣的读者阅读,尤其是在想要读一个框架的代码但是却不知道该按照什么顺序阅读时,本文可以给您一些参考。在这三篇着重于代码解读的文章之后,我会再写一篇梳理OneFlow核心概念的文章,作为精简版,可以快速掌握OneFlow的系统设计。
我们通过介绍一次OneFlow完整运行的流程来了解系统中的各个主要模块是如何协同工作的。
为了方便理解,我们再简要描述一些重要的概念和抽象:
编译期(Compiler)的设计体现了OneFlow作为一个分布式深度学习训练框架的很多重要的设计原则:
1)一致性视角(Consistent View)
OneFlow把整个分布式集群抽象成为一个超级设备,用户使用OneFlow做分布式训练跟做单机单卡的训练没有任何区别。体现在:
2)数据搬运是一等公民
OneFlow将所有的数据加载、预处理、拷贝、网络传输、Tensor的自动切分/拼接/广播/求和操作都抽象成了跟计算Op一样的运行时执行体——Actor,即在分布式的物理计算图上显式表示了数据搬运的操作。这样做的好处是OneFlow可以感知到所有的数据搬运、同步操作,因此编译期Compiler可以更好的在整个物理计算图上做全局调度,使得这些数据搬运操作尽可能被计算操作所掩盖,对数据搬运操作的性能优化转而变成了图分析与图优化。
3)编译期全局调度,运行时去中心化调度
OneFlow的运行时是一个极其简单的抽象——Actor,每个Actor仅需要关心和自己相关的上下游Actor的消息就可以知道自己能否工作,这样做的好处是运行时系统不会因为有中心调度节点导致性能瓶颈(在计算图非常大的情况下)。为了做到这一点,OneFlow的调度工作大多都是在编译期完成的,Compiler会做好全局的内存调度、Op执行调度、通信调度等工作,使得运行时的调度开销尽可能的低,从而达到更快的训练速度。
4)天然支持流水线,解决流控问题
编译期Compiler通过推导和设置Task产出Regst的regst num,可以使得运行时相邻Actor之间可以流水并行起来。同时还可以通过背压机制(Back Pressure)解决流控问题(Control Flow)。具体的Actor机制如何解决流水线和流控问题的讨论我放在下篇中介绍。
在原生的OneFlow设计中,Compiler输入是一个Job(用户定义的op list),经过编译生成OneFlow的中间表示IR(Intermediate Representation)——Plan,Plan是一个被Runtime直接读取就能生成运行时执行图的描述。而上面介绍的OneFlow(JobSet)->MergedPlan是为了支持Python前端交互 + 多Job(Train/Eval同时做)而后设计出来的。我们下面介绍OneFlow的Compiler做了哪些事。
第一步,经过JobCompleter将Job不断重写。经过多个Pass以生成最终的Job。中间借助OpGraph抽象不断推导新的Job对应的逻辑图。这些Pass包括一些优化如插入KeepHeaderOnly节点;增加Source/Sink的Tick节点使得图成为一个单源节点和单汇节点;增加控制边;计算临界区;以及使用XRT框架重新构建Job。
XRT框架会将Job中的OpGraph进行有选择的合并,并选取使用XLA或者TensorRT来进行编译生成优化后的Kernel。对于OneFlow而言,这些都是XrtLaunchOpConf,其Kernel都是XrtLaunchKernel。OneFlow系统并不关心其实现细节,实际上,经过XRT优化后的Kernel实现都是在其框架内定义的顶层抽象:Executable 中存储的,在XrtLaunchKernel的计算过程中调用executable->Run()去执行。
Graph是OneFlow中的一个重要基础抽象,各个重要的图相关的概念(OpGraph、LogicalGraph、TaskGraph、ChainGraph、ExecGraph...)都继承自Graph。Graph表示一个图,里面保存着这个图中的所有的节点Node和节点之间的连边Edge。Graph上面提供一系列共用的遍历方法(普通遍历、拓扑遍历、BFS、DFS...),以及图改写(插入、删除 节点/边)图查询方法。
其实在第一阶段JobCompleter在修改Job的过程中就需要多次Build OpGraph,在最终版本的Job生成以后,我们还需要在全局创建一个OpGraph,用于后续编译过程中对各个逻辑Op和逻辑Tensor的查询。
生成OpGraph分为几步:(核心逻辑:OpGraph::InferLogicalBlobDesc)
按照拓扑序遍历每个Op(OpNode)
1) 推导ParallelSignature (Eager所需)
2) 推导BatchAxis(将要被废弃,描述了哪一个维度是batch维,或者没有batch维,如Variable那一支路上的op)
3) 推导MirroredSignature (推导每个Tensor是否是Mirrored,我认为这个应该跟Sbp成为同一级的东西:SBPM)
4) 推导SbpSignature
SBP是oneflow非常重要的概念,我在知乎文章——《都2020年了,为什么我们相信OneFlow会成功》 中有初步解释了SbpParallel的语义:一种逻辑上的Tensor跟物理上的多个Tensor的映射关系。SbpSignature是一个SbpParallel的集合,在OneFlow的设计里是Op的属性,它描绘了一个逻辑上的Op被映射成各个设备上的多个物理上的Op以后,这些物理上的Op是如何看待他们输入输出Tensor在逻辑上和物理上的映射关系的。
这里的推导SbpSignature,就是在每个Op多个合法的SbpSignature中搜索到一个最优的(传输代价最低的)作为本次训练实际采用的SbpSIgnature。
在自动并行(by @Yipeng1994 )完成以后,推导SbpSignature就不再是按照拓扑序贪心算法推导,而是在全局搜索一个近似次优解。
5) 推导Logical BlobDesc
此处是推导每个逻辑Op的逻辑Tensor的Shape、DType、is_dynamic等信息。
Op最重要的概念就是推导SBP,并根据SBP来推导Tensor的Shape。编译期仅需要静态推导出每个Tensor的形状,以及特殊Op需要推导其Op/Kernel的特殊属性:Inplace、TempBufferSize...
OpGraph是逻辑上的概念,当OpGraph构建完成后,每个(逻辑上的)Op、每个(逻辑上的)Tensor的描述信息都被推导、创建完成了。
LogicalGraph是OneFlow的历史遗留产物,在远古时期负责逻辑图展开、后向生成、Model IO等工作。后面随着OneFlow系统设计的演化,其功能逐步被OpGraph + JobCompleter + Pass所替代。之所以目前还保留,是因为Op与TaskType的映射关系还保留在LogicalNode的不同子类中。在未来一段时间内会移除掉LogicalGraph抽象,完全由OpGraph所取代。
TaskGraph的生成过程是OneFlow编译期最重要也是最精华的一部分。Task是Actor的编译期抽象,Actor是Task的运行时抽象。所以TaskGraph就描绘了整个运行时计算图的全貌。TaskGraph的生成过程分为两部分:
如何根据逻辑图生成物理计算图?
1) 遍历LogicalGraph的每个LogicalNode,根据每个LogicalNode的placement:生成有序的ComputeTaskNode(专用于计算的TaskNode)
2) 遍历LogicalGraph的每个LogicalEdge,
在远古时期的OneFlow设计中,生成SubTaskGraph的方法是跟前后LogicalNode的类型相关。而在后面的boxing重构中(by: @liujuncheng, 见:Oneflow-Inc/oneflow#2248 和 Oneflow-Inc/oneflow#2846 等),生成SubTaskGraph的方法被SubTskGphBuilder所推导,根据情况构建纷繁多样的SubTaskGraph。下面会粗略介绍一下其中的设计。
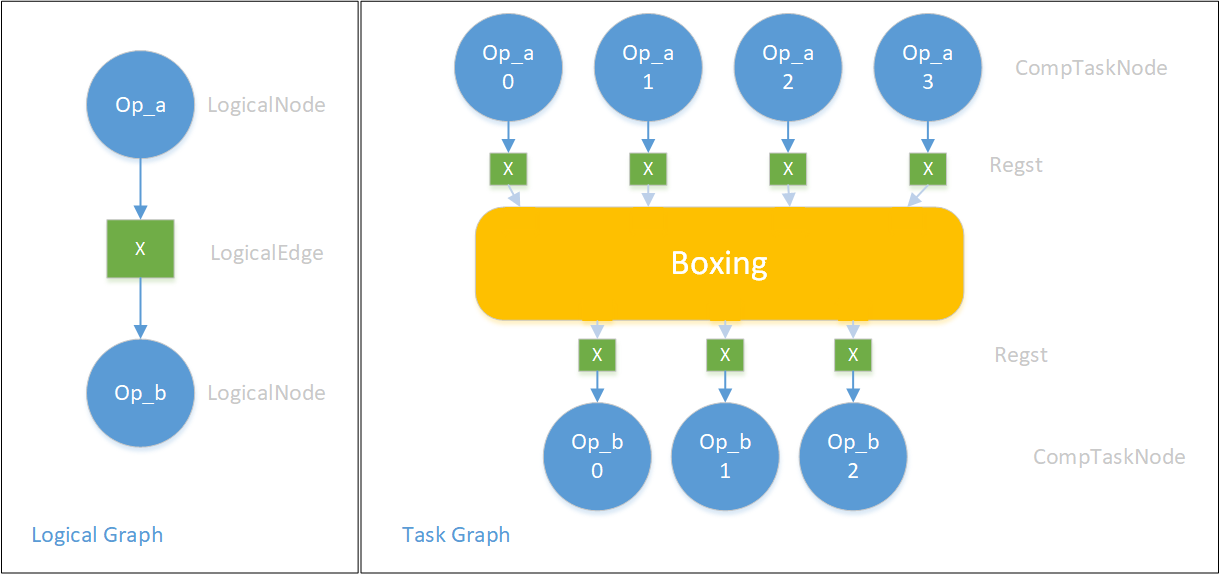
下图展示了一种可能的SubTaskGraph构建方式:在LogicalGraph中,逻辑上的Op_a产出一个Tensor X 供Op_b消费,其中Op_a和Op_b的Placement分别是4,3,而Op_a和Op_b对X的SBP parallel根据各自Op的属性、用户指定/推导/自动SBP的结果确定。Tensor X就是一条LogicalEdge。第一步:分别生成所有LogicalNode对应的有序的ComputeTaskNode,Op_a的LogicalNode展开成4个CompTaskNode,Op_b的LogicalNode展开成3个ComputeTaskNode。第二步:这些ComputeTaskNode在Boxing架构中会根据实际情况新增节点,并连边,使得下面Op_b的3个TaskNode可以拿到其想要的那部分X的数据。
每个LogicalEdge就是一个逻辑上的Tensor,前后两个逻辑上的Op对同一个Tensor的SBP、Placement看待可能一致也可能不一致。如何构建这部分SubTaskGraph对应的子图呢?OneFlow提供了一系列SubTskGphBuilder,根据各种情况生成不同的子图。
构建该子图需要的全部信息是: 源节点的CompTaskNode列表,汇节点对应的CompTaskNode列表,源节点与汇节点的并行属性(ParallelDesc,SBP),传输的逻辑Tensor的信息(Shape、Dtype、LogicalBlobId...)
目前OneFlow内部有7种SubTskGphBuilder,每种Builder下面都可以根据SBP、Placement等信息自定义多种实际的构图方案,如SliceBoxingSubTskGphBuilder下面就有5种不同的构图情况,CollectiveBoxingSubTskGphBuilder下面又有7种集合通信的Builder。 我们这里简单介绍几个常见的子图构建方式:
1) one to one
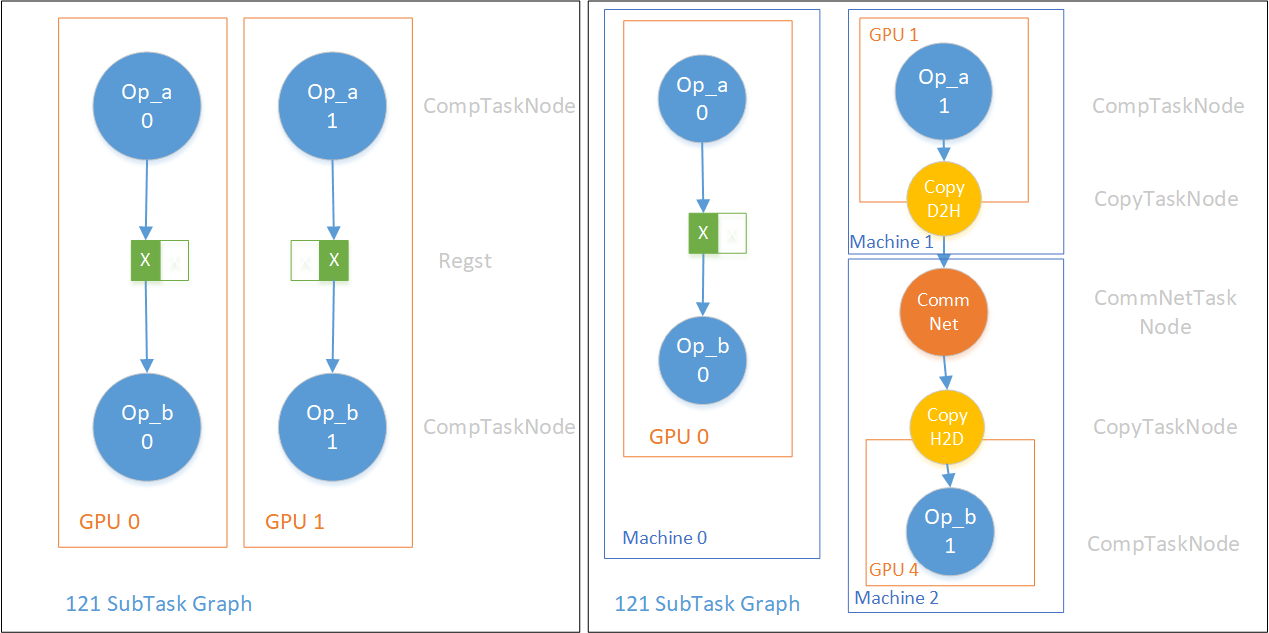
这是最常见的连接方式,即LogicalEdge的两端节点在ParallelNum、SBP上对中间逻辑Tensor的看待方式完全一致,可以一对一的直连。在常见的数据并行情况下(如Mirror的方式),前后向Op都是一对一直连的。下图展示了两种一对一直连情况。
左边是GPU内部的一对一直连,右边是当两个ComputeTaskNode不在同一个设备上时,我们会插入传输节点:CopyD2H(Device to Host),CopyCommNet(网络传输),CopyH2D(Host to Device),使得一对一直连的汇节点CompTaskNode可以拿到对应的Tensor。
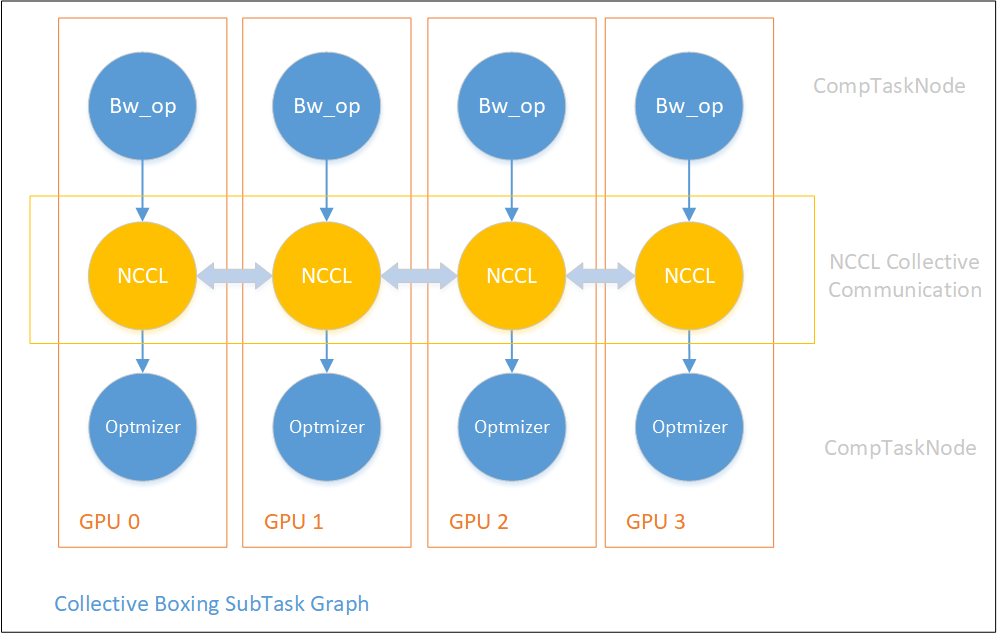
2) collective boxing
集合通信(Collective Communication)大多采用NCCL的实现,包含了:AllReduce、ReduceScatter、AllGather、Reduce、Broadcast等操作。需要注意的是:
下图展示了OneFlow中使用NCCL进行集合通信的collective boxing操作构图。
3) slice boxing
这种boxing涵盖了oneflow中遇到的大多数跟SBP相关的Boxing。在SliceBoxingSubTskGphBuilder中提供了支持S2B、S2S、P2S、P2B、B2S等5种不同的SBP情形。
slice boxing会根据上下游两组CompTaskNode的ParallelDesc、SBP的不同,把上面一组物理上的Tensor按照下游期望的SBP的方式分配给下游的一组CompTaskNode,同时考虑Machine id、CPU/GPU的不同,同时希望传输开销、构图开销尽可能少。
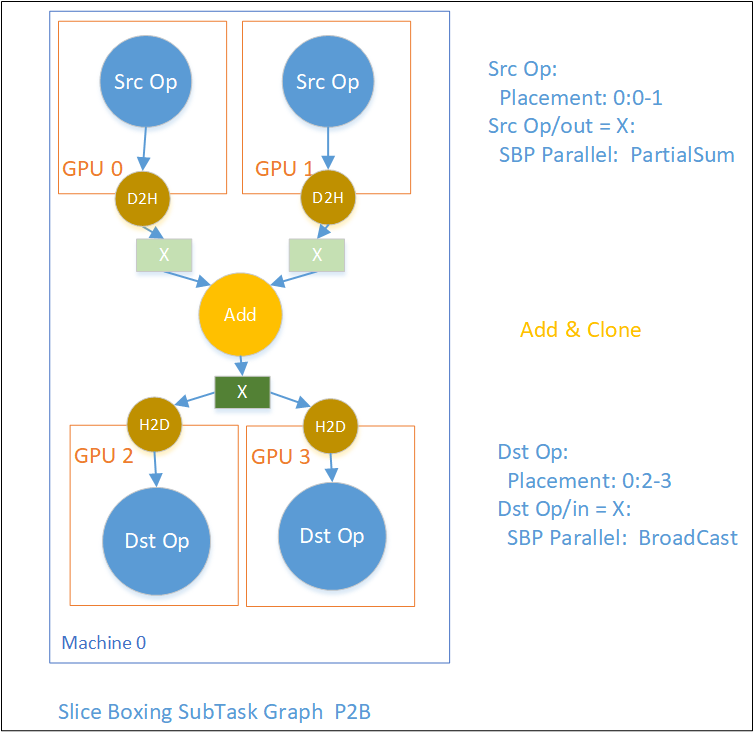
下图展示了一种可能的S2S的slice boxing 情形。逻辑图上SrcOp产出Tensor X供DstOp消费,其中SrcOp在Machine0的GPU0、1以及Machine1的GPU2、3上产出SBP Parallel = Split(0) 的Tensor X,而DstOp在Machine3的GPU4、5以及Machine 4的GPu6上消费SBP Parallel = Split(0)的Tensor X。故需要把已经分成4份的Tensor X 先concat起来,然后再split成3份分发给各个DstOp。
我们再举一个可能的P2B的例子。Src Op产出的两个物理Tensor X分别是逻辑Tensor X的一部分值,经过Add和Clone操作发给后面以Broadcast消费X的两个DstOp。
OneFlow中的Boxing设计是其分布式易用性以及分布式性能上最精华的一部分,这里仅介绍了其概况,后续会单独出一篇文章分享其中的设计。
我们通过SubTaskGraphBuilder给每个LogicalEdge对应的物理子图构图,这样就搭建起了整个TaskGraph,完成了逻辑图到物理图的映射。构图过程中,根据节点类型等信息可以给每个TaskNode分配Thread id、Area id等属性。
Thread id 标记了每个TaskNode(即Actor)工作在哪个线程上。由于分布式环境下每个机器上是一个进程,所以每个TaskNode都会设置Machine id和Thread id。线程id分配的方式:CPU上是平均分配各个thread id;GPU上,同一个GPU的所有计算Task在同一个计算线程中;所有集合通信的Task在同一个NCCL线程中。这样分配线程id的方式是因为经过实验验证,计算Task在相同线程中速度最快(最小切换开销)。
Area id 【即将过时】标记了不同类型的Op、TaskNode分别从属于整个TaskGraph上的哪一个区域。有一些特殊的Area如kMdUpdtArea 标记了这些Task是在Optimizer子图部分的。然而Area id是一个过时设计。应该被完备的Scope概念所取代,同时一个Op从属于哪个Area也不是Op的类型决定的,而是Op在编译期图重写的哪一个阶段被插入所决定的。后续会把Area id移除。
在目前的设计中,TaskGraph还会生成ChainGraph,进行Chain的合并,给每个Task上新增Chain id的属性,用于将一组Task子图标记出来(方便做内存复用)。
被合并到一个Chain中的这组Task有一个共性:在相同的Thread/Stream中执行,当Chain子图中的源节点可以执行以后,Chain子图的所有后继节点可以一股脑的执行完,不需要依赖或者再等其他的节点。
Chain的合并算法在远古时期以Layer为单位进行遍历合并时是可以较好工作的,但是目前以Op为单位就显得有些过时,尤其是在一些特殊的网络(如包含where op)中会因为图的拓扑遍历顺序的不同而有较大的合并效果差异,甚至是成环的BUG。
目前仅在内存复用算法中依赖了Chain的合并结果。后续会重构掉这块,将Chain的概念从TaskNode中去掉。
在TaskGraph的构图完毕之后,Compiler会按照TaskGraph中TaskNode的拓扑序遍历,依次构建每个TaskNode对应的各种信息:
1) 生成每个TaskNode的所有Regst,并把Regst绑定到TaskNode的出边TaskEdge上。TaskNode::ProduceAllRegstsAndBindEdges
2) 将每个TaskNode的入边TaskEdge中的Regst关联到TaskNode中
3) 执行每个TaskNode的Build过程
TaskNode根据其不同的TaskType 有对应的TaskNode子类特化。每种类型的TaskNode其构建过程都不同。最常见的是NormalForwardCompTaskNode,对应了所有用户定义的计算Op的Actor。每种TaskNode对应一种Actor,其Actor内部执行的状态机也不同。oneflow/core/graph/路径下列出了目前所有种类的TaskNode子类及实现。
TaskNode的构建过程中,内部需要构建Regst。
Regst是OneFlow中数据存储、传递的基本单元。运行时Actor之间的消息通信,数据传递都使用Regst。在目前的Regst设计中,一个Regst会包含多个Blob(广义上的Tensor概念),但越来越多的需求是需要一个Regst仅包含一个Blob,后续的重构中,会把Blob概念整合进Tensor中,精简这里的概念。
Tensor是用户级别的概念,是独立的的一块数据,而Regst是Actor级别的概念,记录了这个Regst是由哪个Actor生产的,并被哪些Actor所消费的。
TaskNode内部会有一个ExecGraph(执行子图),执行子图上的节点称之为ExecNode,边称之为ExecEdge。在远古的OneFlow设计中,每个TaskNode里是由多个Op组成的执行子图构成的,每个Op对应一个ExecNode,后面随着性能优化变成了一个TaskNode对应一个Op。我们仍然保留了ExecGraph的设计,虽然在目前的绝大多数场景中ExecGraph里只有一个ExecNode,没有ExecNode。
ExecNode 和 Op 的区别:(虽然我不止一次希望把ExecNode和Op合并)
在OneFlow最初的设计中,Op是一个描述概念,并不关心具体的某个Blob/Tensor,仅提供一系列方法用于推导,Op是无状态的。而ExecNode是在某个具体的TaskNode内部,同时要关联具体的Regst,是有状态的。
1) ExecGraph:绝大多数TaskNode的Build过程都是根据LogicalNode中的Op(CompTaskNode)/ 新建Op (CopyTaskNode),先构建ExecGraph。
2) ExecNode:bind regst。在TaskNode中,入边消费的Regst和出边生产的Regst内部都维护了一个或多个lbi(logical blob id),用于标识一个Blob(Tensor)。TaskNode的构建过程中需要把这些Regst里的lbi跟Op内部的BnInOp绑定起来。
3) ExecNode: InferBlobDesc。 推导每个Blob/Tensor的Shape等信息(存储在BlobDesc中)
在TaskGraph Build结束以后,原本的Compiler还会对整个TaskGraph进行一些优化。在前后向分离、python前端的重构中,Compiler这里的优化被精简成了几步:
1) 移除空的Regst
2) 增加Chain内的控制边保证执行顺序
3) 推导Inplace的内存共享
Inplace的推导使用了 InplaceLbiGraph 进行推导。需要注意的是,我们在Op(UserKernel)里定义的SetInplaceProposalFn 仅是一种“建议”,而实际上这个Op的输出和输入能否Inplace,还需要经过InplaceLbiGraph进行推导以后才能决定。一些显而易见的约束是,一个Tensor不能同时被两个消费它的Op进行Inplace,因为Inplace会改写输入的Tensor数据,是一种Mutable消费。Inplace在一些情况下可以加速计算。
4) 推导时间形状(time shape)
在OneFlow的Regst中,除了其中的数据有物理上的形状,Regst本身也有时间形状(time shape),表示整个网络执行一个Batch的数据,该Regst需要被生产几次。time shape 有2维,最常见的是(1, 1),表示一个batch执行一次。一些特殊的Op/Actor会修改时间形状: Repeat/Acc、Unpack/Pack。由于这些特殊Op可能会嵌套,所以我们让时间形状有两维,表示最多允许两层嵌套。当网络中插入一个Repeat Op,会把该Tensor重复发送k次,其时间形状就是(1,k)。当网络中插入Unpack Op,会把一个Tensor切分成k段,按k次分别发送给后面的Op(相当于在时间上一种数据并行)。
如果网络中连续插入多个RepeatOp,比如第一个Repeat将输出的时间形状修改为(1, k1),后续的Regst均为该时间形状;再插入第二个Repeat,则输出的时间形状会被修改为( k2, k1)。
最终TaskGraph中的每个TaskNode会生成Plan中的TaskProto,得到一个naive的Plan。
Plan里最重要的内容就是所有的TaskProto,每个TaskProto就描述了运行时的一个Actor所需的所有信息。
在naive的Plan生成之后,Improver会把Plan进行改写。
Improver的最初设计是为了推导RegstNum。
在我之前的两篇知乎文章中,都提到了运行时Actor机制的相邻Actor流水线是通过RegstNum > 1来实现的。naive_plan中没有推导RegstNum,所以所有的RegstNum均=1。而Improver中设计了一套算法,用于推导每个TaskNode对应的RegstNum,但是算法依赖每个Actor的实际执行时间。所以需要有试跑。
在TaskGraph中我们hack了代码,使得所有的CopyHdTaskNode的MinRegstNum=2,也就是RegstNum=2,目的是为了让数据预处理跟GPU计算可以流水并行起来,未来会删除掉这个hack。TaskGraph上对于每个Regst都推导了其min、max的regst num,一般的数据Regst min = 1, max = inf。也有的regst,我们不希望有任何多余的备份,故让这些Regst min = 1,max = 1。
由于试跑对于后续的OneFlow开发非常不友好,于是Improver这里的试跑一直都没有被启用。而且即使所有的RegstNum = 1,在非相邻的两个Actor之间也可以流水并行起来。
目前Improver中最重要的目的是为了推导内存复用。内存复用也经历了多个阶段,一开始是使用一种染色算法对Regst进行染色,相同颜色的共用一段内存。后续我设计开发了内存复用2.0(见 Oneflow-Inc/oneflow#2267、Oneflow-Inc/oneflow#2319),采用了Chunk、MemBlock、Regst三级内存结构,仍使用Improver作为入口。所以complete_plan中会比naïve plan新增了Chunk和MemBlock的信息。OneFlow中的内存复用设计后续会单独出一篇文章进行分享。
后续会将内存复用算法放在Compiler中,使得Compiler的结果就是最终的Plan。
至此,我们就描述清楚了如何从一个Job编译成一个Plan的全过程。
小结
本文是OneFlow系统设计分享文章的中篇,主要介绍OneFlow完整运行流程的中间部分:编译期Compiler将Job编译成Plan的过程。在下一篇《仅此一文让您掌握OneFlow框架的系统设计(下篇)》中,我们会介绍OneFlow的运行时(Runtime)以及仓库源码下的主要各目录的模块简介,其中会包含Actor运行时如何高效的调度,以及如何解决流水线和流控问题。
OneFlow完整运行流程 & 各个模块之间交互方式
4. 编译期: Compiler(Job)->Plan
4.1 JobCompleter().Complete(job)
4.2 生成OpGraph
4.3 生成LogicalGraph 【即将过时】
4.4 生成TaskGraph
4.4.1 构图部分
根据前后LogicalNode的类型,找到对应的生成这部分SubTaskGraph的方法:BuildSubTaskGraphMethod,执行该方法给这两个LogicalNode对应的ComputeTaskNode连边、新增节点构图。
SubTskGphBuilder

ChainGraph 【即将过时】
4.4.2 TaskGraph的Build/Infer阶段
TaskNode
Regst
TaskNode的Build过程
4.4.3 TaskGraph & Plan 优化
4.4.4 生成Plan
4.5 Improver(naive_plan) -> complete_plan