概述
人脸识别技术可以准确识别出图像中的人脸和身份,具有丰富的应用场景,譬如金融场景下的刷脸支付、安防场景下的罪犯识别和医学场景下的新冠流行病学调查等等。人脸识别的算法演变经历了以 PCA 为代表的早期阶段,再到以“人工特征+分类器”为主的统计学习方法阶段,近几年,随着大数据及 GPU 算力的爆发,人脸识别进入到深度学习算法为绝对主角的阶段。混合并行 的方式解决超大规模人脸识别 问题,已经成为工业界的最佳实践,但主流深度学习框架(如TensorFlow, PyTorch, MXNet等)仅支持了更容易实现的数据并行,而如果要实现混合并行,往往需要基于深度学习框架进行二次开发且编程复杂度高。
OneFlow 作为主打分布式易用和性能的框架,有着去中心化的Actor机制及SBP的抽象,天然对分布式有着良好支持,训练速度快、显存占用低,同样的显卡能支持更大的batch size,从单机多卡拓展到多机分布式训练并不需要复杂的设置。本文基于OneFlow实现了大规模人脸识别的解决方案,该方案可以帮助用户轻松使用数据并行 + 模型并行的混合训练,同时还支持了 Partial FC 采样技术,理论上支持过亿(ID数)级别的人脸识别。
InsightFace 是基于 MXNet 框架实现的业界主流人脸识别解决方案。相较MXNet的实现方案 ,基于OneFlow的实现方案在性能方面更是十分优秀,OneFlow在数据并行时速度是其2.82倍;模型并行时速度是其2.45倍;混合并行+Partial fc时速度是其1.38倍。基于OneFlow实现的代码已合并至 insightface的官方仓库 ,其中包含了数据集制作教程、训练和验证脚本、预训练模型 以及和MXNet模型的转换工具。在 The 1:1 verification accuracy on InsightFace Recognition Test (IFRT) 验证集上,Oneflow及MXNet训练模型的精度对比如下:
Framework
African
Caucasian
Indian
Asian
All
OneFlow
90.4076
94.583
93.702
68.754
89.684
MXNet
90.45
94.60
93.96
63.91
88.23
仓库地址:https://github.com/deepinsight/insightface/tree/master/recognition/oneflow_face
下面,将以大规模人脸识别任务为例,介绍基于OneFlow和MXNet 框架是如何现业界流行的大规模人脸识别技术,以及数据并行、模型并行以及Partial FC采样 的实现细节,主要内容包含:
完全理解本文的技术内容需要对 OneFlow 的并行观和原理有所了解,OneFlow团队曾写过几篇文章详细介绍了OneFlow的并行观、SBP属性等概念,有需要的读者可参考:
1.大规模人脸识别背景介绍
前面的概述简单介绍了人脸识别的一些应用场景以及超大规模人脸识别所带来的一些挑战,下面将更具体一点,来分析下大规模人脸识别方案中涉及到的关键技术以及具体难在何处。
1.1 面临的问题
简单的网络
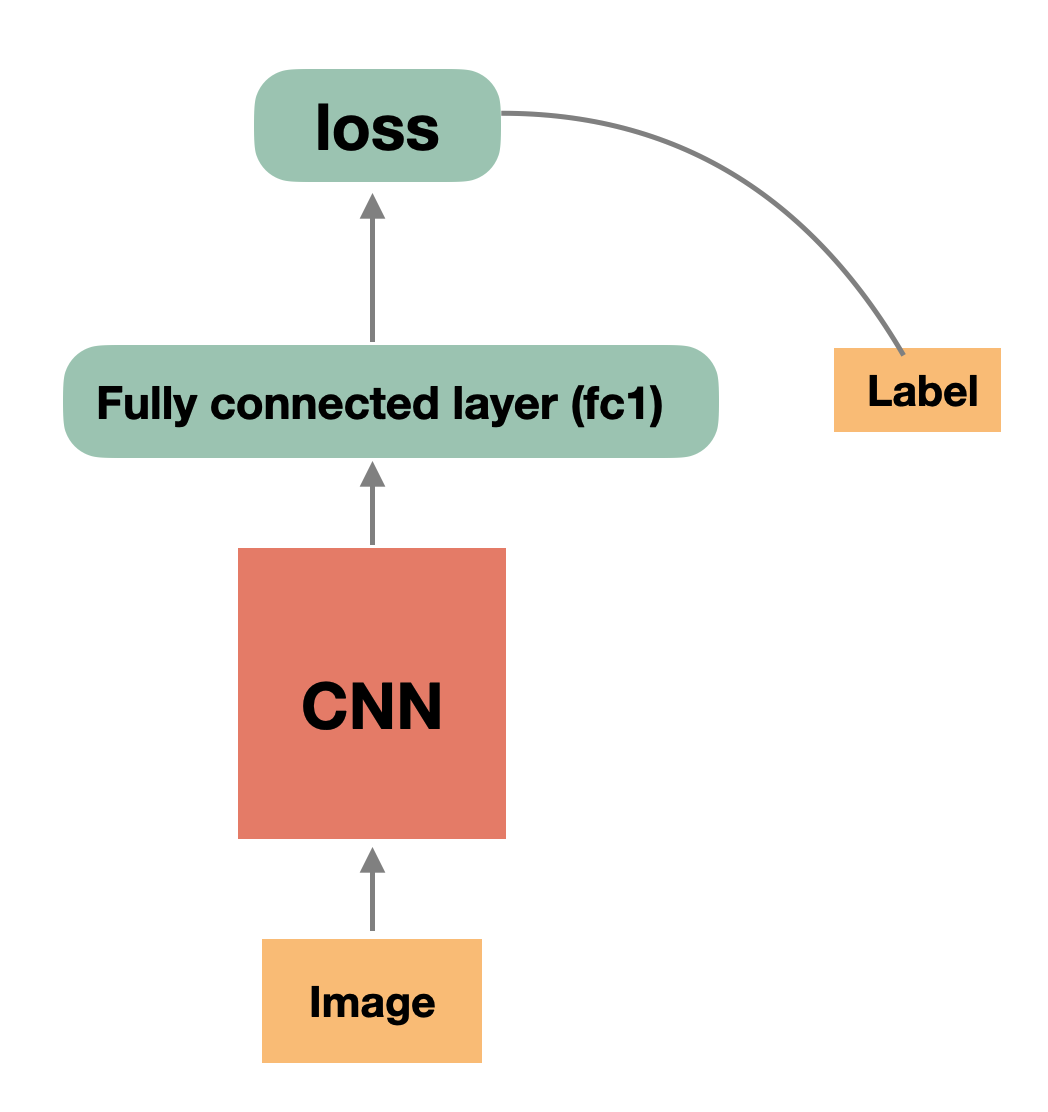
基于深度学习网络的大规模人脸识别方法一般都是基于常规的 CNN 网络(如resnet50、resnet100等)来提取输入图片中的人脸特征,然后人脸特征会输入到全连接层,最后基于全连接的输出计算 Loss,单纯从网络结构来看,大规模人脸识别相关的网络通常如下图所示:
复杂的MarginLoss
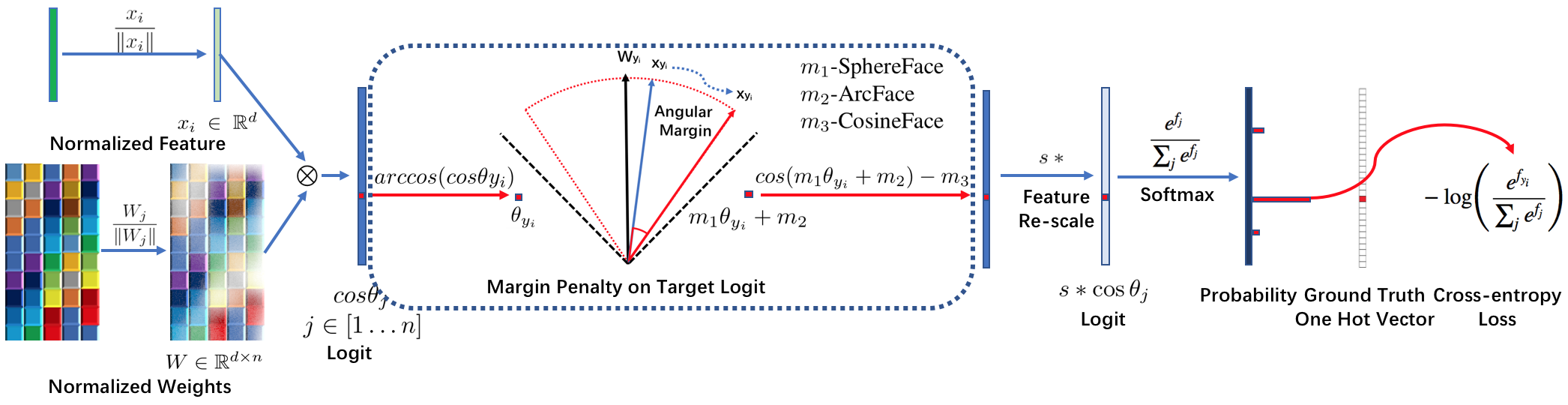
大规模人脸识别面临的第一个问题是,当使用常规的CNN+FC的网络,后接softmax交叉熵损失函数来对人脸进行分类时,往往得到的结果并不能令人满意,同一个人在不同角度,不同光线等情况下,往往会得到不一样的分类结果。所以在最后计算交叉熵损失之前,需要通过一些方法对FC层的输出进行处理,譬如加入特征间距离的度量,用于判断类别内部(同一个人的不同脸部)和外部(不同人脸间)之间的差异大小。简单来说,一个鲁棒的人脸分类模型应该可以使得映射后的特征具有较小的类内和较大的类间距离。
通过这种基于类间、类内距离度量的方法衍生出了一系列距离度量损失函数,如 center loss、triplet loss、sphereface loss、cosface loss、arcface loss 等等。其中arcface loss源于论文《ArcFace: Additive Angular Margin Loss for Deep Face Recognition》 ,由于应用了超球面度量、余弦距离等创新方法,其对于类间和类内距离度量更为精准,在各种人脸识别任务和数据集上表现优异。
MarginLoss 类:
class MarginLoss (object) :""" Default is Arcface loss
"""
def __init__ (self, margins=(1.0 , 0.5 , 0.0 ) , loss_s=64 , embedding_size=512 ) :"""
"""
self.loss_m1 = margins[0 ]
self.loss_m2 = margins[1 ]
self.loss_m3 = margins[2 ]
self.loss_s = loss_s
self.embedding_size = embedding_size
def forward (self, data, weight, mapping_label, depth) :"""
"""
with autograd.record():
norm_data = nd.L2Normalization(data)
norm_weight = nd.L2Normalization(weight)
fc7 = nd.dot(norm_data, norm_weight, transpose_b=True )
mapping_label_onehot = mx.nd.one_hot(indices=mapping_label,
depth=depth,
on_value=1.0 ,
off_value=0.0 )
if self.loss_m1 == 1.0 and self.loss_m2 == 0.0 :
_one_hot = mapping_label_onehot * self.loss_m3
fc7 = fc7 - _one_hot
else :
fc7_onehot = fc7 * mapping_label_onehot
cos_t = fc7_onehot
t = nd.arccos(cos_t)
if self.loss_m1 != 1.0 :
t = t * self.loss_m1
if self.loss_m2 != 0.0 :
t = t + self.loss_m2
margin_cos = nd.cos(t)
if self.loss_m3 != 0.0 :
margin_cos = margin_cos - self.loss_m3
margin_fc7 = margin_cos
margin_fc7_onehot = margin_fc7 * mapping_label_onehot
diff = margin_fc7_onehot - fc7_onehot
fc7 = fc7 + diff
fc7 = fc7 * self.loss_s
return fc7, mapping_label_onehot
MarginLoss包含m1~m3这3个参数,通过这3个参数的组合来实现cosface loss和arcface loss。而在oneflow中的实现中则更为简便,直接调用flow.combined_margin_loss 即可实现MarginLoss系列的功能。
巨大的人脸ID数导致显存爆炸
对于工业界的人脸识别业务,人脸 ID 数通常会超过百万级,甚至可以达到千万级至亿级别,在这种情况下全连接层的参数矩阵通常会超出单个 GPU 设备的显存上限,所以,仅仅靠普通的数据并行也无法完成训练。而这就是大规模人脸识别方案的核心挑战所在。
1.2 解决方案
数据并行 or 模型并行
为了处理上面提到的问题,工业界对于超大规模的人脸识别任务,往往采用数据并行 + 模型并行的混合并行方式。即在网络前面的CNN部分,采用数据并行进行人脸特征提取,而最后的全连接层则采用模型并行,将参数矩阵切分到多个 GPU 上。
2.OneFlow 如何实现大规模人脸识别
基于OneFlow实现的大规模人脸识别方案对齐了 insightface官方的partail_fc 的实现(基于MNXet),支持数据并行、数据|模型混合并行和Partial FC采样技术,在loss方面支持设置了 m1,m2和m3超参以定义 softmax loss、arcface loss、cosface loss 以及其他组合形式的 combined loss。代码已合并至insightface官方仓库—oneflow_face 。
下面将通过整体结构和技术细节实现这两个层面来介绍基于OneFlow的大规模人脸识别方案。
2.1 整体结构
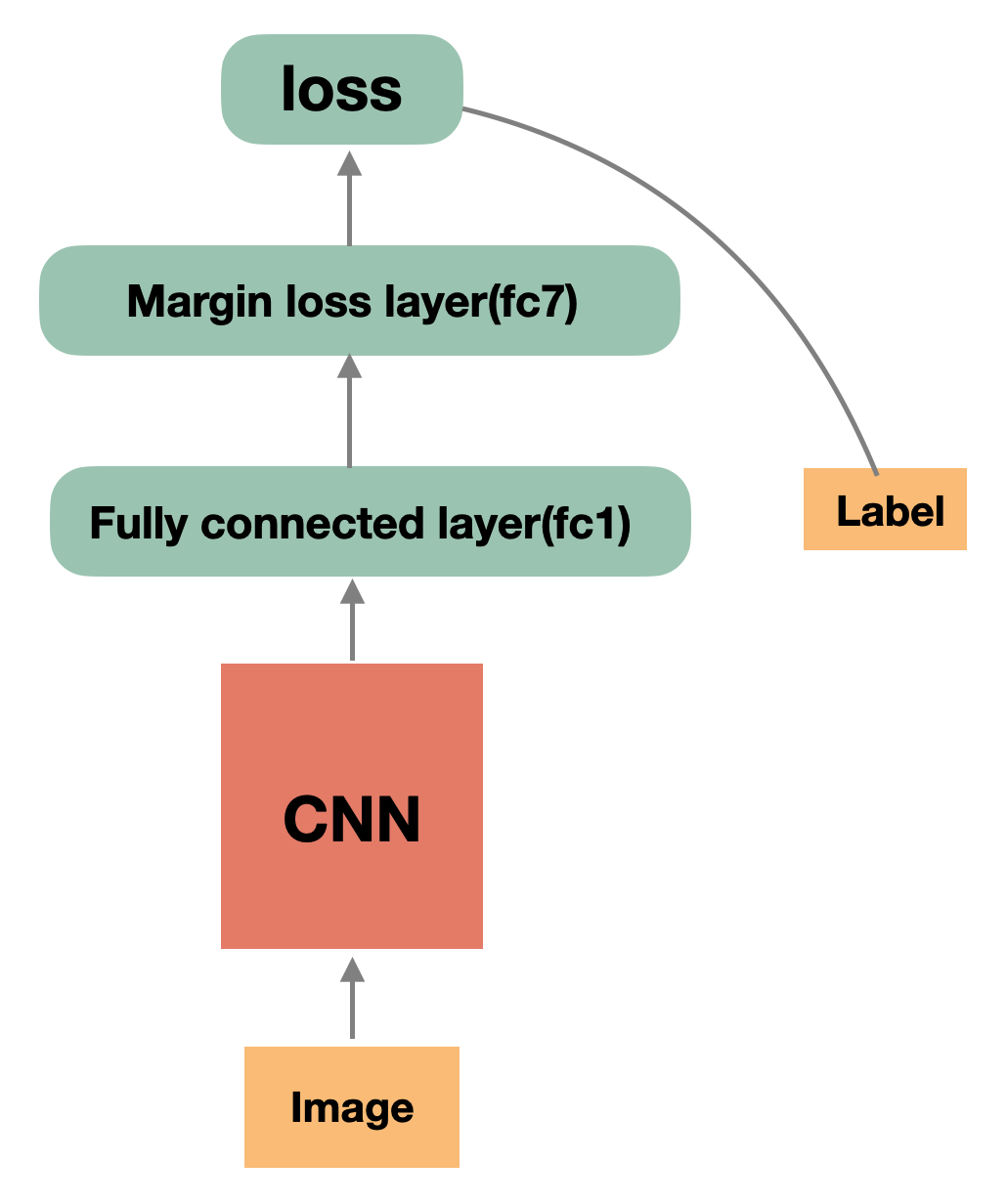
首先是 采用数据并行的CNN 特征提取部分 ,CNN提取的特征(Features)作为后面的全连接(FC)层的输入,全连接层采用模型并行 。全连接层fc1经过Margin loss layer(fc7)处理后的输出,同label一起计算softmax交叉熵损失,得到最终的loss。
整体的网络结构如下图:
FC层以及具体loss计算的细节,如下图所示:
对于batch_size大小的批量图片输入,Feature的形状为 (batch_size, emb_size),emb_size根据网络不同通常为128或512。图中的权重(Weight)的大小与人脸类别 ID 数有关,在大规模人脸识别的工业实践中,类别 ID 数通常为百万到亿级别,假设类别 ID 数为1千万,则模型大小为(emb_size, 10000000)。经过全连接层的特征矩阵和权重矩阵相乘后((batch_size, emb_size) × (emb_size, 10000000))的输出特征形状为 (batch_size, 10000000)。
在OneFlow的实现方案中全连接层采用模型并行,即对权重矩阵做切分而使用全量的特征数据,因此输入特征的 SBP 属性为 Broadcast,即表示每个GPU设备上都会拷贝一份特征数据;而权值的 SBP 属性为 Split(1),即参数矩阵在维度1被切分到各个 GPU 设备上,假设有 P 个 GPU,则每个 GPU 上有 (emb_size, 10000000/P) 大小的权值 。全连接层的输出形状取决于输入features的形状以及类别ID数,故每个设备上的输出形状为 (batch_size, 10000000/P),且 SBP 属性也为 Split(1)。
由于本方案对权值做了切割(Split(1)),故通常来说,需要对全连接层的输出做合并,并转为按 Split(0) 切分的数据并行,但是由于全连接层的输出数据块较大,如果直接由 Split(1) 转为 常规的Split(0),会引入大量(可以避免的)通信。因此,在 OneFlow 算子实现的内部,并不先进行 Split 的转化,而是将全连接层的输出直接作为 softmax 的输入进行计算,因为 softmax 的运算特性,可以使得输出的 SBP 属性依然是 Split(1)。类似的,softmax 的输出(按 Split(1) 切分)继续作为 sparse_cross_entropy 的输入进行计算,由于算子本身的特性和 OneFlow 的机制,sparse_cross_entropy 的输出的 SBP 属性依然可以保持 Split(1)。
经过 sparse_cross_entropy 处理后的输出,逻辑上获得最终的 loss 结果。 此时,数据块的形状为 (batch_size, 1),已经很小,这时候再将模型并行的Split(1)模式转为按 Split(0) 切分的数据并行。
以上即是 OneFlow 实现的全连接层的内部工作流程,对于普通算法开发者来说,了解以上内容即掌握了OneFlow大规模人脸方案中全连接层处理的核心流程。对于框架开发者和实现细节感兴趣的朋友,请看下面的小节—2.全连接层的技术细节。这一小结,将会用较大篇幅展开softmax和sparse_cross_entropy实现细节相关的内容以及Split(1)切分是如果做到数学上的等价。
2.2 Oneflow实现代码解析
下面,我们讲解一下在Oneflow是如何通过简单的几行代码来实现大规模人脸识别方案。首先,backbone部分的网络是类似的由CNN+FC全连接层构成,我们重点看一下FC之后的Marginloss层及相关处理。主要代码如下:
elif config.loss_name == "margin_softmax" :
if args.model_parallel:
print("Training is using model parallelism now." )
labels = labels.with_distribute(flow.distribute.broadcast())
fc1_distribute = flow.distribute.broadcast()
fc7_data_distribute = flow.distribute.split(1 )
fc7_model_distribute = flow.distribute.split(0 )
else :
fc1_distribute = flow.distribute.split(0 )
fc7_data_distribute = flow.distribute.split(0 )
fc7_model_distribute = flow.distribute.broadcast()
fc7_weight = flow.get_variable(
name="fc7-weight" ,
shape=(config.num_classes, embedding.shape[1 ]),
dtype=embedding.dtype,
initializer=_get_initializer(),
regularizer=None ,
trainable=trainable,
model_name="weight" ,
distribute=fc7_model_distribute,
)
if args.partial_fc and args.model_parallel:
print(
"Training is using model parallelism and optimized by partial_fc now."
)
(
mapped_label,
sampled_label,
sampled_weight,
) = flow.distributed_partial_fc_sample(
weight=fc7_weight, label=labels, num_sample=args.total_num_sample,
)
labels = mapped_label
fc7_weight = sampled_weight
fc7_weight = flow.math.l2_normalize(
input=fc7_weight, axis=1 , epsilon=1e-10 )
fc1 = flow.math.l2_normalize(
input=embedding, axis=1 , epsilon=1e-10 )
fc7 = flow.matmul(
a=fc1.with_distribute(fc1_distribute), b=fc7_weight, transpose_b=True
)
fc7 = fc7.with_distribute(fc7_data_distribute)
fc7 = (
flow.combined_margin_loss(
fc7, labels, m1=config.loss_m1, m2=config.loss_m2, m3=config.loss_m3
)
* config.loss_s
)
fc7 = fc7.with_distribute(fc7_data_distribute)
else :
raise NotImplementedError
loss = flow.nn.sparse_softmax_cross_entropy_with_logits(
labels, fc7, name="softmax_loss"
)
lr_scheduler = flow.optimizer.PiecewiseScalingScheduler(
base_lr=args.lr,
boundaries=args.lr_steps,
scale=args.scales,
warmup=None
)
flow.optimizer.SGDW(lr_scheduler,
momentum=args.momentum if args.momentum > 0 else None ,
weight_decay=args.weight_decay
).minimize(loss)
return loss
和MXNet的实现类似,fc1表示backbone网络最后的全连接层输出;fc7表示后面的Marginloss层。在模型并行的情况下,需要分别设置数据、fc1、fc7层的SBP属性:
fc1_distribute = flow.distribute.broadcast()
fc7_model_distribute = flow.distribute.split(0 )
fc7_data_distribute = flow.distribute.split(1 )
设置SBP属性后,Oneflow框架会根据其SBP属性及内在的Boxing机制,在后续前向反向的过程自动完成模型切分、数据的同步、以及内在的调用集合通信源语来完成broadcast、allreduce相关操作。 接下来,获取fc7层的权重矩阵fc7_weight,其SBP形状为fc7_model_distribute设定的模型切分。接着会判断是否使用Partial fc采样,如果使用,则通过flow.distributed_partial_fc_sample()获取采样后的权重及label。
1.首先,通过flow.matmul()进行矩阵乘法(fc1层->fc7层的前向传播),并设置其结果的SBP属性为fc7_data_distribute。
2.然后,通过flow.combined_margin_loss()完成fc7层的前向传播,由于其SBP属性并没有改变,故继续设置其SBP属性为fc7_data_distribute。
3.最后,直接调用flow.nn.sparse_softmax_cross_entropy_with_logits()即可完成求softmax交叉墒损失,至此完成了整个过程前向+loss计算,之后的反向过程、梯度更新、学习率更新等将由后面的flow.optimizer自动完成。
2.3 模型并行的技术细节
上文已经介绍了OneFlow 大规模人脸方案的整体实现,实现中全连接层采用模型并行,即全部的数据与部分的模型进行 matmul 运算,其原理示意可参考 Consistent 与 Mirrored 一文中的相关部分,之后对matmul的结果进行 softmax+求交叉熵损失函数,即调用flow.nn.sparse_softmax_cross_entropy_with_logits()完成整个计算过程。
可能,有的读者会好奇,模型并行下的softmax是如何通过一个sparse_softmax_cross_entropy_with_logits计算得到的?模型并行下的计算和正常情况下的计算数学上等价吗?这一小节,将详细介绍在FC层模型并行下的softmax交叉熵计算过程,以及其数学上为何等价。
问题产生的原因
首先,正常|数据并行情况下的softmax过程要求对全局数据进行softmax,即对label和完整的特征(模型)进行数学计算,但在模型并行的实现方案中,由于全连接层为模型并行,故softmax的计算方式和正常方案有所不同。
在OneFlow的模型并行方案中,label与部分的模型进行 matmul 运算,然后直接在各卡本地计算 softmax,最终通过 sparse cross entropy 算子计算得到 SBP 属性为 Split(1) 的 loss,最终将 loss 的 SBP 属性转为 Split(0), 即转为和普通数据并行方案等价的loss。因此,看起来和普通的softmax方案会存在差异,那么这就带来了这两种方案下的softmax计算在数学上是否等价的问题!
下文介绍此问题产生的原因以及 OneFlow 的 flow.nn.parse_softmax_cross_entropy_with_logits 算子,是如何在模型并行的情况下做到数学上softmax计算等价的。
模型并行下的softmax
在逻辑上,全连接层后,应该进行 softmax 运算,其公式如下:
在实际的深度学习框架实现中,为避免数值溢出,往往会调整以上公式,让指数部分减去数据中的 max 值。 也就是说,实际采用的公式为:
此时,由于本方案采用模型并行,每个设备上只有部分的模型,如果在每张卡本地直接套用以上 softmax 公式,就会出现问题:
公式中涉及到的求 max 和求 sum 的运算均需要全局的信息
如果在求 max 和求 sum时忽略掉全局信息,只对每张卡独立地、使用本地数据进行 softmax 计算,得到的结果与数学上的要求不一致。但是,如果将全局信息,也就是全连接层的输出广播到各个 GPU 设备上,假定类别 ID 数为10000000,则数据块的大小为 (batch_size, 10000000),通信代价较高,因此如何高效地分布式完成 softmax 计算也常是其它框架在实现模型并行时面临的难题之一。
下面,将介绍 OneFlow 的算子 flow.nn.parse_softmax_cross_entropy_with_logits 的内部实现原理和细节,可以看到它利用 OneFlow 框架 SBP 机制,是如何巧妙地解决以上问题。
sparse_softmax_cross_entropy_with_logits 的实现细节
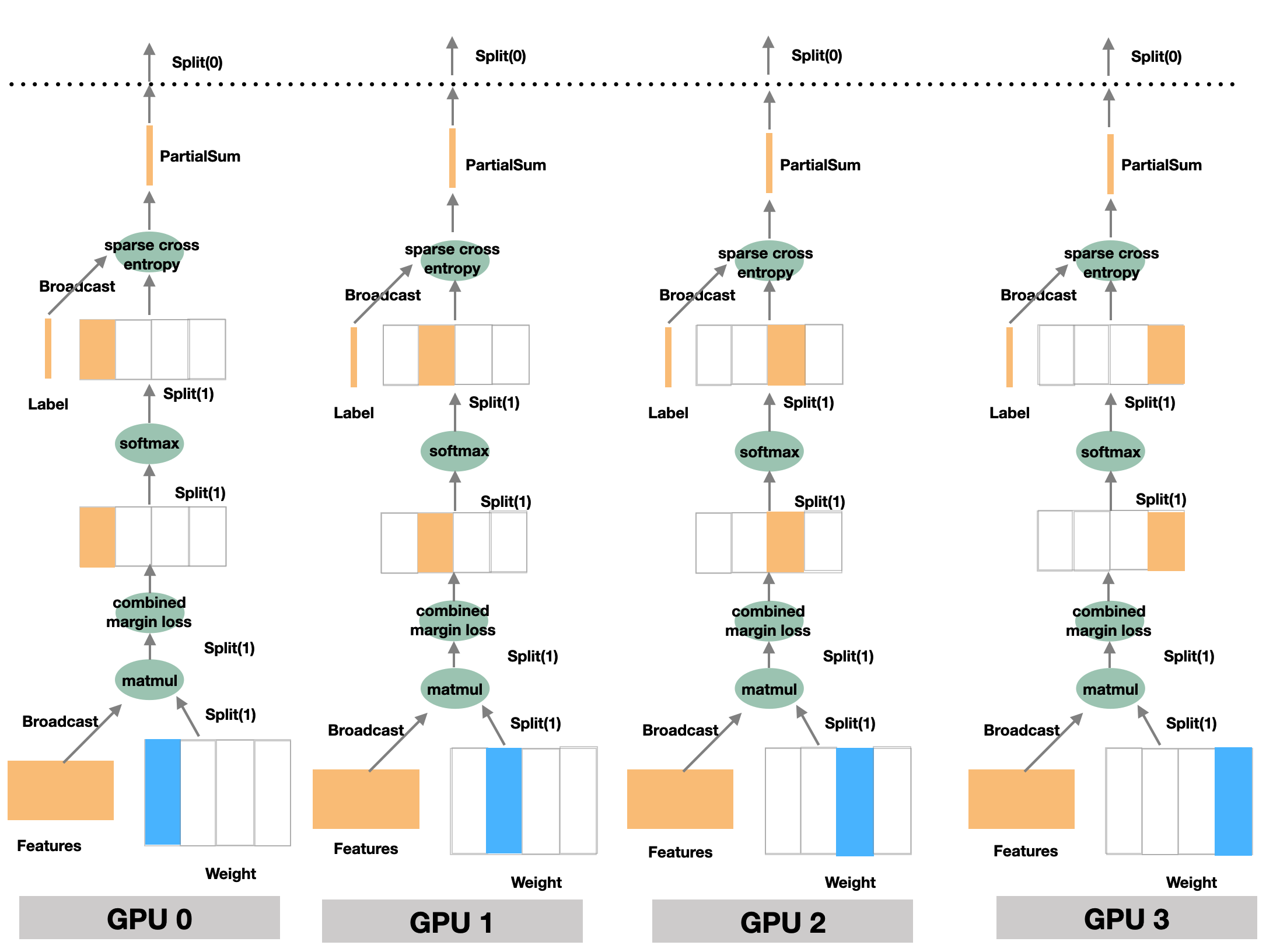
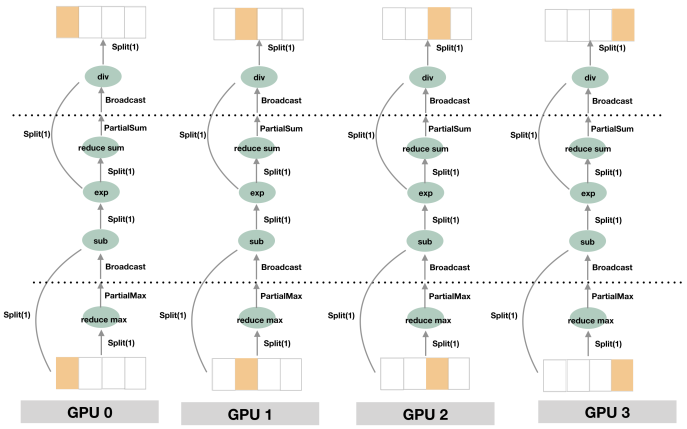
为了解决以上产生的分布式计算softmax的问题,本方案将逻辑上的全局 softmax,在网络内部拆分成多个Operator(op)进行计算/操作,在经过reduce max、sub、exp...等一系列op计算后,最终得到全局 softmax 的等价计算结果,以下是具体实现的示意图:
reduce max
reduce max的作用是按列取出最大,以形状为 (3, 3) 的数据块为例,其效果为:
[5 , 4 , 2 ] [5 ]
[4 , 3 , 3 ] -reduce max-> [4 ]
[1 , 9 , 8 ] [9 ]
这样,在每个卡上经过独立的 reduce max 运算后,得到 Partial max 的结果,即每个 GPU 设备上是部分结果。 此时,数据的块的形状已经变小为 (bathc_size, 1),为了将多个 GPU 上的 Partial max 结果求 max 得到全局的max结果,需要将每张卡上的部分max结果广播到其他卡,这样每张卡上都能获取到全局max结果,在这一步骤中虽然仍然不可避免地需要 AllReduce 通信,但是因为 reduce max 后的数据块已经大大减小,因此降低了通信成本。
sub
接着,可以进行逻辑上的减法操作,即图中的 Sub。Sub 的输入有两个:来自全连接层的输出(SBP 属性为 Split(1)),以及上一步计算得到的全局 max 的结果(SBP 属性为 Broadcast),OneFlow 可以自动推导出,Sub 后的输出结果的 SBP 属性为 Split(1) 。
exp
然后,减法的输出,经过图中的 Exp 运算,完成了原数学公式中的分子的求解。需要多说明一句的是,Sub 及 Exp 的过程中,都保持了 Split(1) 的性质,因此数据块小,效率高。
reduce sum
再之后,需要继续求解原数学公式中的分母,此时需要使用 reduce sum 运算,同上文介绍的 reduce max 类似,reduce sum 计算取得的结果其实只是单独卡上的局部结果,即 Partial sum,后续需要一次 Broadcast 通信并计算,才能得到全局 sum 的结果。
div
得到数学公式中的分子分母后,使用 Div 算子得到他们相除的结果,Div 的输入为之前步骤计算得到的数学公式中的分子与分母,其中分子的 SBP 属性为 Split(1),分母的 SBP 属性为 Broadcast。OneFlow 可以自动推导出,相除的结果的 SBP 属性为 Split(1)。
可以看到以上过程,利用多个算子在 OneFlow 框架下的运算,既做到了与数学逻辑上的要求一致,又很大程度地降低了多个设备之间的通信量 ,因为 Partial max 及 Partial sum 过程中,通信的数据块大小均为 (batch_size, 1)。接着求最终loss,从上文的介绍可知,softmax 的输出的 SBP 属性为 Split(1),需要继续经过 sparse cross entropy 计算得到 loss。
sparse cross entropy 的输入有两个:
前一层 softmax 的输出,SBP 属性为 Split(1)
OneFlow 会根据 sparse cross entropy 输入的 SBP 属性,自动推导出其输出的 SBP 属性为 Partial sum。 sparse_cross_entropy 的输出,经过 Partial sum 后,再广播到各个卡,同 softmax 的情况类似,因为数据块已经经过减小,因此大大减少了通信量。
OneFlow 中的代码实现
上文详细讨论了人脸识别网络的全连接层,及其后续网络在 OneFlow 中如何用一系列算子(op)进行实现。从理解原理的角度出发,以上讨论的篇幅较长,但对于普通的分布式训练用户而言,使用 OneFlow 实现大规模人脸方案的代码却极为简洁 :
labels = flow.parallel_cast(labels, distribute = flow.distribute.broadcast())
embedding = flow.parallel_cast(embedding, distribute = flow.distribute.broadcast())
fc7 = flow.layers.dense(
inputs=embedding,
units=args.class_num,
model_distribute=flow.distribute.split(0 ),
)
loss = flow.nn.sparse_softmax_cross_entropy_with_logits(
labels, fc7.with_distribute(flow.distribute.split(1 )), name="softmax_loss"
)
在以上代码中,先使用 flow.parallel_cast 方法将 labels 和 embedding 的 SBP 属性设置为 Broadcast。然后,在flow.layers.dense内通过设置其 model_distribute 参数为 flow.distribute.split(0) 将模型的 SBP 属性设置为 Split(1),从而创建了模型并行方式的全连接层。
最后,通过调用 flow.nn.sparse_softmax_cross_entropy_with_logits 获取 loss。 上文讨论原理中所涉及的 SBP 类型推导、SBP 属性转换等工作,都由 OneFlow 框架自行完成。
3.MXNet的大规模人脸识别方案
基于MXNet实现的大规模人脸方案面临的主要问题主要有:
混合并行模式下常规的算子如gloss.SoftmaxCrossEntropyLoss 无法正常工作的问题。
MXNet的解决方案为采用horovod、类似numpy的mxnet.ndarray对矩阵进行手动切分计算和手写softmax交叉熵相关的代码,整体实现相对复杂。下面我们将对MXNet实现方案的实现流程做简单讲解,包含前向、反向和Marginloss相关部分。
3.1 MXNet实现代码解析
模型训练入口是 train_memory.py 中的 train_module.fit() :
train_module.fit(train_data_iter,
optimizer_params=backbone_kwargs,
initializer=mx.init.Normal(0.1 ),
batch_end_callback=call_back_fn)
通过调用 SampleDistributeModule 类中定义的 fit 方法来开启整个训练过程。在 fit 方法中除了会对模型的参数做初始化外,还主要包括以下内容:
通过 update() 调用 optimizer 完成对模型、学习率等参数的更新。
下面将重点讲解forward_backward() 中前向、反向这两个部分的具体流程。
def forward_backward (self, data_batch) :"""A convenient function that calls both ``forward`` and ``backward``.
"""
total_feature, total_label = self.forward(data_batch, is_train=True )
self.backward_all(total_feature, total_label)
前向
前向代码如下:
def forward (self, data_batch, is_train=None) :if is_train:
self.num_update += 1
fc1 = self.backbone_module.get_outputs()[0 ]
label = data_batch.label[0 ]
total_features = self.allgather(tensor=fc1,
name='total_feature' ,
shape=(self.batch_size * self.size,
self.embedding_size),
dtype='float32' ,
context=self.gpu)
total_labels = self.allgather(tensor=label,
name='total_label' ,
shape=(self.batch_size *
self.size, ),
dtype='int32' ,
context=self.cpu)
return total_features, total_labels
else :
return None
其中 backbone_module 主要是提取图片特征,如果不添加Marginloss层,则人脸识别网络的架构是由一个CNN接FC层组成,然后通过softmax交叉熵计算损失函数。如果添加了Marginloss层则还需要对Marginloss做相关的处理,在MXNet的实现中将Marginloss层的前向和反向过程一起放在了下面的backward_all()函数中。
反向
由前向部分的描述可知,反向部分包括两个主要部分: 1.Marginloss层的处理 2.普通CNN网络的反向 下面,我们看一下backward_all()方法:
def backward_all (
self,
total_feature,
total_label,
) :'grad_cache' ,
total_feature.shape)
self.loss_cache = self.get_ndarray(self.gpu, 'loss_cache' , [1 ])
self.grad_cache[:] = 0
self.loss_cache[:] = 0
if not bool(config.sample_ratio - 1 ):
grad, loss = self.backward(total_feature, total_label)
else :
grad, loss = self.backward_sample(total_feature, total_label)
self.loss_cache[0 ] = loss
total_feature_grad = grad
total_feature_grad = hvd.allreduce(total_feature_grad, average=False )
fc1_grad = total_feature_grad[self.batch_size *
self.rank:self.batch_size * self.rank +
self.batch_size]
self.backbone_module.backward(out_grads=[fc1_grad / self.size])
其中:
第1部分,对Marginloss层的处理集中放在了backward()和backward_sample()部分,二者区别在于backward()对应的是sample_ratio=1.0时的反向(不使用Partial fc进行采样);backward_sample()对应使用Partial fc进行采样时的反向过程。
第2部分,实现CNN网络的反向,即:self.backbone_module.backward
通过这两个部分,完成了整个反向过程的梯度计算。下面重点看一下第1部分对Marginloss层的处理。
Marginloss
首先,看一下backward()的代码结构:
def backward (self, total_feature, label) :assert memory_bank.num_local == memory_bank.num_sample, "pass"
_data = self.get_ndarray2(self.gpu, "data_%d" % self.rank,
total_feature)
_data.attach_grad()
memory_bank.weight.attach_grad()
_label = self.get_ndarray2(self.gpu, 'label_%d' % self.rank, label)
_label = _label - int(self.rank * memory_bank.num_local)
_fc7, _one_hot = self.fc7_model.forward(_data,
memory_bank.weight,
mapping_label=_label,
depth=memory_bank.num_local)
max_fc7 = nd.max(_fc7, axis=1 , keepdims=True )
max_fc7 = nd.reshape(max_fc7, -1 )
total_max_fc7 = self.get_ndarray(context=self.gpu,
name='total_max_fc7' ,
shape=(max_fc7.shape[0 ], self.size),
dtype='float32' )
total_max_fc7[:] = 0
total_max_fc7[:, self.rank] = max_fc7
hvd.allreduce_(total_max_fc7, average=False )
global_max_fc7 = self.get_ndarray(context=self.gpu,
name='global_max_fc7' ,
shape=(max_fc7.shape[0 ], 1 ),
dtype='float32' )
nd.max(total_max_fc7, axis=1 , keepdims=True , out=global_max_fc7)
_fc7_grad = nd.broadcast_sub(_fc7, global_max_fc7)
_fc7_grad = nd.exp(_fc7_grad)
sum_fc7 = nd.sum(_fc7_grad, axis=1 , keepdims=True )
global_sum_fc7 = hvd.allreduce(sum_fc7, average=False )
_fc7_grad = nd.broadcast_div(_fc7_grad, global_sum_fc7)
tmp = _fc7_grad * _one_hot
tmp = nd.sum(tmp, axis=1 , keepdims=True )
tmp = self.get_ndarray2(self.gpu, 'ctx_loss' , tmp)
tmp = hvd.allreduce(tmp, average=False )
global_loss = -nd.mean(nd.log(tmp + 1e-30 ))
_fc7_grad = _fc7_grad - _one_hot
_fc7.backward(out_grad=_fc7_grad)
_weight_grad = memory_bank.weight.grad
self.memory_optimizer.update(weight=memory_bank.weight,
grad=_weight_grad,
state=memory_bank.weight_mom,
learning_rate=self.memory_lr)
return _data.grad, global_loss
其中fc7_model即MarginLoss 所在的层,细节如论文所示,这里就不展开了。backwark()方法里首先通过fc7_model.forward()完成将开始Marginloss层的前向过程并得到以及one_hot的label:
_fc7, _one_hot = self.fc7_model.forward(_data,
memory_bank.weight,
mapping_label=_label,
depth=memory_bank.num_local)
然后计算softmax交叉墒损失,再通过反向产生梯度。
通过调用 gloss.SoftmaxCrossEntropyLoss 即可完成softmax交叉墒损失的计算,不过对于数据+模型的混合并行的情况,MXnet 现有的api无法支持,需要手动实现整个softmax交叉墒的计算。具体来说就是通过下面一系列max、sum、div的计算再加上 allreduce 和 broadcast 集合通信操作共同完成。反向传播完成后,再通过self.memory_optimizer.update完成optimizer里模型权重的更新、学习率的更新。
通过以上代码分析,可以看出基于 MXNet实现的人脸识别方案还是比较复杂的,除了要求算法开发者对整个人脸识别流程、模型数据的切分和softmax交叉熵数学计算比较熟悉,还需要对分布式集合通信原理、horovod的使用较为熟练。整体来看,要求还是比较高的。
4.数据并行、模型并行解决方案的通信量对比
这一小结将介绍传统的数据并行方案、以及本方案(数据+模型并行)中涉及到的通信量做大致分析及对比。
4.1 数据并行通信量
首先,若采用纯数据并行,假定人脸类别 ID 数为10000000,涉及的通信量为大模型的反向梯度的 Allreduce,数据块大小为 (emb_size, 10000000), 若采用 RingAllReduce,总传输量为:
2 * emb_size * 10000000 * (P - 1)
4.2 混合并行通信量
让我们对纯数据并行与本文的混合并行两种解决方案的通信量进行比较,采用本文的混合并行,涉及的通信量由以下几部分组成:
1.CNN 网络得到的人脸特征由 Split(0)->Broadcast 的传输,数据块大小为 (batch_size, emb_size)
2.label 由 Split(0)->Broadcast 的传输,数据块大小为 (batch_size, 1)
3.Softmax 计算过程中,每卡 Split(1) 切分数据的 max 值由 Partial max->Broadcast 的传输,数据块大小为(batch_size, 1);每卡 Split(1) 切分数据的 sum 值由 Partial sum->Broadcast 的传输,数据块大小为(batch_size, 1)
4.最终算出 loss 后的通信,数据块大小为 (batch_size, 1)
因此,假设 GPU 数目为 P,则总传输量为:
(batch_size * emb_size + 6 * batch_size) * (P - 1)
4.3 对比总结
不难算出,当batch_size大小及显卡数P一定、且人脸类别 ID 数巨大时(譬如1000万),纯数据并行和基于本方案的混合并行,二者通信量存在数量级的差异:
2 * emb_size * 10000000 * (P - 1) VS batch_size * (emb_size + 6) * (P - 1)
采用数据并行时,巨大的人脸类别 ID 数导致的显存占用可能撑爆显存使得无法训练,即使可以训练,巨大的通信量也会使得吞吐率降低,训练速度变慢。而采用OneFlow混合并行方案时,不仅可以大大降低显存占用,提升训练速度,此外假定 GPU 数目为 P,则在连接层每个 GPU 上的模型是总模型大小的1 / P,可以通过扩展GPU设备数,支持超大规模的类别 ID 数。
5.Partial FC采样技术
模型并行,可以解决巨大的人脸分类ID带来的权重存储和通信问题,因为无论类别多大,总可以通过扩展GPU设备数来解决。然而,在矩阵乘法的实现中,除了模型权重矩阵之外,全连接层fc1输出的embedding特征矩阵也同样需要存放在GPU显存中:
fc7 = flow.matmul(
a=fc1.with_distribute(fc1_distribute), b=fc7_weight, transpose_b=True
)
在模型并行的方案中,当模型并行到P台设备上时,每卡的embedding尺寸为:
(batch_size_per_device * P, emb_size)
当设备数P逐渐增大时,embedding矩阵同样会消耗大量内存,导致实际支持的最大人脸ID类别数也有上限,即不能通过无限拓展设备数P来支持更大规模的ID类别数。为了解决此问题,格林深瞳在论文《Partial FC: Training 10 Million Identities on a Single Machine》 提出了Partial FC的采样技术,简单来说,Partial fc即对矩阵的一种采样 ,通过设置相应的采样率(sample ratial)来达到节省内存,能支持更大类别数的效果。
根据论文中的描述,softmax函数中的负类在人脸表征学习中的重要性并没有那么高,即无需用每个输出特征和完整的模型权重矩阵相乘(全采样),可以通过sample ratial设置采样率,譬如sample ratial=0.1则表示只采样10%的权重矩阵,而经过采样后不损失精度,通过此方式可以轻松支持更大类别数。insightface相关的代码在官方仓库:insightface/partial_fc 。
OneFlow中也支持了Partial FC采样的功能,只需调用flow.distributed_partial_fc_sample算子即可对权重矩阵、标签label进行采样。使用Partial FC采样的主要代码如下:
(mapped_label, sampled_label, sampled_weight) = flow.distributed_partial_fc_sample(
weight=fc7_weight, label=labels, num_sample= num_sample)
6.OneFlow和MXNet实现的性能对比
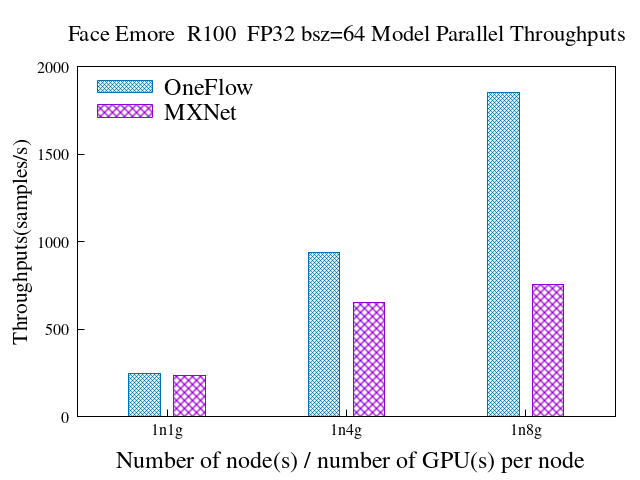
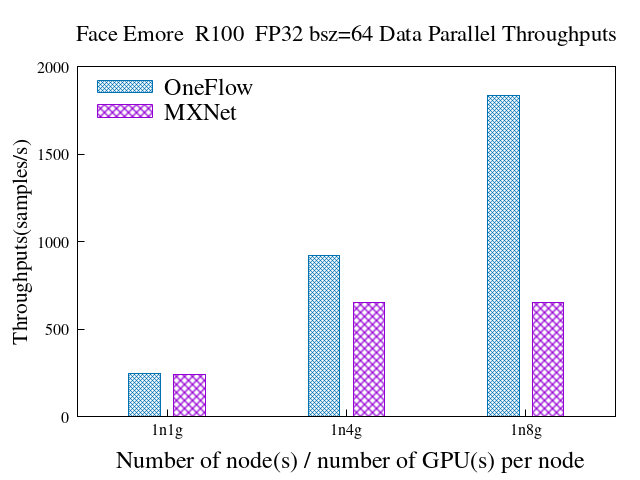
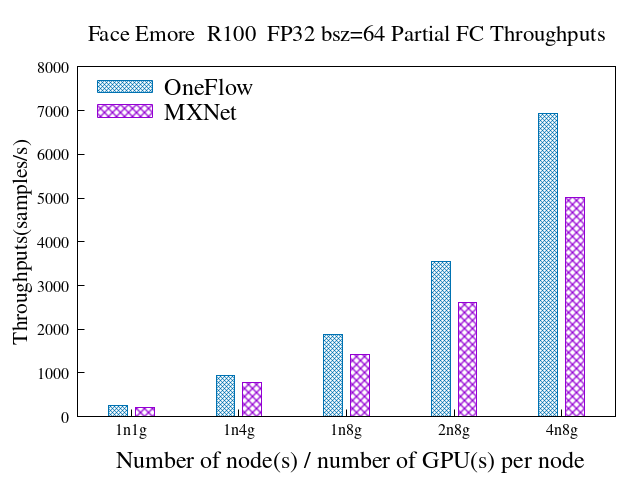
我们在相同硬件环境下,测试了基于MXNet和OneFlow框架实现的大规模人脸识别方案,从吞吐率(速度)、支持的最大batch size、支持的最大人脸ID数规模等指标对两个方案进行了对比。总体来说,基于OneFlow实现的大规模人脸方案,在单机、多机情况下的表现均大幅由于MXNet实现,具体表现在:
1.在相同batch size下,吞吐率更高,训练速度更快且多 卡时,性能损失较小,更接近线性加速比。其中:
数据并行时,1836.8 vs 650.8(samples/s),速度是MXNet的2.82倍
模型并行时,1854.15 vs 756.96(samples/s),速度是MXNet的2.45倍
混合并行+Partial fc时(4机32GPU),6931.6 vs 5008.7(samples/s),速度是MXNet的1.38倍,且加速比28.1 vs 22.8
2.对GPU显存的管理水平和利用率更高 ,在相同硬件配置下(gpu显存固定时)支持跑更大的batch size
模型并行时,115 vs 96,较MXNet提升20%
混合并行+Partial fc时,115 vs 96,较基于MXNet实现的Partial fc提升20%
3.支持更大规模的人脸ID类别数
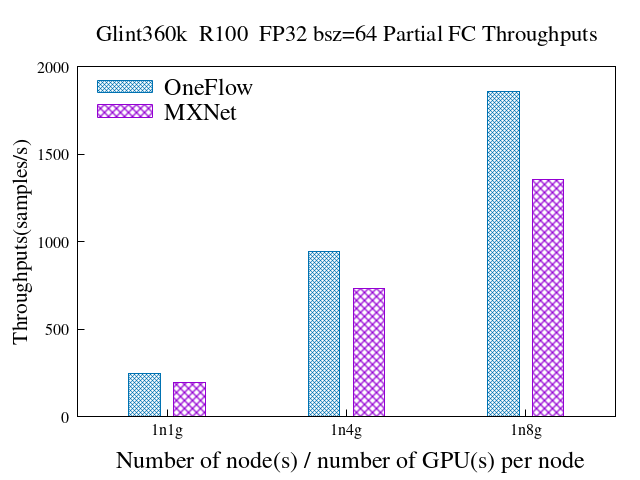
混合并行+Partial fc时,单机支持的最大人脸ID数(num classes):1350万 vs 1200万,较基于MXNet的Partial fc提升12.5%
具体数据见下面的图表。
6.1 数据并行
FP32 & Batch size = 64
OneFlow
MXNet
node_num
gpu_num_per_node
samples/s
speedup
samples/s
speedup
1
1
245.0
1
241.82
1
1
4
923.23
3.77
655.56
2.71
1
8
1836.8
7.50
650.8
2.69
6.2 模型并行
FP32 & Batch size = 64
OneFlow
MXNet
node_num
gpu_num_per_node
samples/s
speedup
samples/s
speedup
1
1
245.29
1
233.88
1
1
4
938.83
3.83
651.44
2.79
1
8
1854.15
7.55
756.96
3.24
6.3 混合并行 + Partial FC(sample ratio = 0.1)
emore数据集
FP32 & Batch size = 64
OneFlow
MXNet
node_num
gpu_num_per_node
samples/s
speedup
samples/s
speedup
1
1
246.45
1
218.84
1
1
4
948.96
3.85
787.07
3.6
1
8
1872.81
7.60
1423.12
6.5
2
8
3540.09
14.36
2612.65
11.94
4
8
6931.6
28.13
5008.72
22.89
glint360k数据集
FP32 & Batch size = 64
OneFlow
MXNet
node_num
gpu_num_per_node
samples/s
speedup
samples/s
speedup
1
1
245.12
1
194.01
1
1
4
945.44
3.86
730.29
3.76
1
8
1858.57
7.58
1359.2
7.01
6.4 Max batch size per device
以下数据为单机8卡、fp32精度模式下测得,旨在比较相同硬件环境下,不同框架对GPU显存的管理利用能力,以训练时所能支持的最大batch size大为优。
OneFlow
MXNet
dataset
max batch size per device
max batch size per device
glint360k
115
96
6.5 Max num classes
以下数据为单机、fp16混合精度模式下测得,旨在比较相同硬件环境下,不同框架所能支持的最大人脸ID类别数(num classes),以比较框架的性能边界。
mode
node_num
gpu_num_per_node
max num classes(OneFlow)
max num classes(MXNet)
AMP
1
1
2000000
180 0000
AMP
1
8
13500000
1200 0000
所有数据、测试报告及代码见DLPerf仓库: https://github.com/Oneflow-Inc/DLPerf#insightface
7.总结
随着深度学习及GPU算力的爆发,以深度学习算法为基础的人脸识别方案已经得到广泛应用,人脸识别方案相关的深度学习网络通常以CNN为主,其网络结构通常较为简单,但难点在于超大规模人脸模型的训练上。通常由于类别数非常大,导致模型大小通常超出单张显卡的显存上限,所以不得不使用数据并行+模型并行的方式来进行训练,而各大框架对此类需求支持的并不是很好,工业/企业落地时往往需要需要算法工程师、框架开发工程师对各大深度框架进行二次开发或深度定制,实现起来往往较为复杂且训练效率得不到保障。
通过上文与MXNet实现的性能对比可以看出,使用OneFlow 实现的(数据+模型混合并行)超大规模人脸识别方案,其优势有:
扩展性强、可以轻松支持千万、最大支持亿级别的类别 ID 数的人脸识别模型。
不增加额外通信,在 FC 层甚至大大降低了通信量,训练速度更快,更近线性加速比。
速度和灵活性上的优势得益于SBP的抽象以及以分布式易用性为出发点的系统设计,OneFlow实现数据并行/模型并行方案只需要很少量的代码,无需对dataset、optimizer、model等做额外包装、无需使用horovod等第三方工具,对算法开发工程师来说更为友好。
8.致谢
OneFlow复现、调试Insightface的过程中,需要特别感谢Insightface项目的发起人过佳以及Partial fc的作者格灵深瞳的安翔。首先感谢两位提供了如此高效的大规模人脸识别方案,其次,在OneFlow方案实现过程中,他们给出了耐心细致的指导,在数据集、测试方面也给予了大力支持,衷心感谢!
撰文:郭冉、赵露阳 OneFlow团队 2021年2月25日